Research
Following the finalisation of project requirements, the project members delved into how they could best complete this project. They came up with several approaches, each with its own advantages and disadvantages. By critically discussing the different methods with their TAs, IXN Mentor, and professor, they were able to deduce the best method that not only aligned with the project requirements but also optimised resources, minimised risks, and maximised potential for success.
1. Related Projects Review
Unfortunately, at the time the research was conducted, LLMs had not been commercially available for a long time - meaning that research into similar LLM-guided hazard classification was sparse. To minimise the effects of trudging blindly into uncharted territory, the members decided to research other aspects of LLMs that would benefit the project. This included the most important factor in LLMs, prompting, as well as the benefits and trade-offs that quantised models provided.
1.1 Prompting
Prompting is arguably the most important factor to consider when dealing with LLMs. Even the slightest changes in the prompt can have the LLM produce vastly different responses. [1] As thus, the team spent a substantial amount of time experimenting with prompts and researching further into how to craft the perfect prompt.
In the final deliverable, there were two instances in which the powers of an LLM were utilised. This included the tool itself (with its API call to ChatGPT to identify potential hazards within a report), as well as the generation of the Association Matrix (with its call to Llama2 to generate likelihood scores that one hazard was associated with another). In both cases, similar effective prompt engineering techniques were used. This section will describe techniques that the project members employed to effectively generate more accurate responses that were utilised in both cases of invocations.
1.1.1 General Techniques to prompting LLMs
There are three general techniques that are used in prompt engineering. [2]
- Zero, one, and few-shot prompting
- Chain-of-thought prompts
- Zero-shot chain-of-thought prompts
Although chain-of-thought and zero-shot chain-of-thought prompting may have yielded better results, the group members decided that its use of a significantly larger context window violated the project’s goal of being a cost-effective and faster solution. OpenAI (ChatGPT) charges according to number of input and output tokens, meaning that the group members were constantly trying to minimise the amount of tokens that would be needed and generated. Whilst the costs may not seem much during testing, when formally handed over to the IFRC and used by multiple people at once, the costs would add up over the course of time.
OPENAI_PRICING_USD_PER_1K_TOKENS = {
'prompt': {
'gpt-3.5-turbo': 0.002,
'gpt-4-32k': 0.06,
'gpt-4': 0.03,
},
'completion': {
"gpt-3.5-turbo": 0.002,
'gpt-4-32k': 0.12,
'gpt-4': 0.06,
}
}
In addition, latency increases according to the number of tokens; a larger number of input and output tokens means that the LLM would be considerably slower to generate. [6] As thus, the relatively-token-sparing n-shot prompting technique was employed in this particular scenario.
![Figure 1.1.1b: A series of graphs comparing the number of completion tokens to the generation (response) time for different LLMs. Credit: [9]](/2023/group38/assets/images/Untitled-a83d34919fc431fa364f7804ee179643.png)
Figure 1.1.1b: A series of graphs comparing the number of completion tokens to the generation (response) time for different LLMs. Credit: [9]
These series of graphs demonstrate that the completion time is directly correlated to the generation time.
1.1.2 n-shot Prompting
n-shot prompting is a method of prompt engineering in which the prompt contains n examples of the desired outcome. [3] n=0 means that no examples are provided, and that it is wholly up to the LLM to generate a valid response that is beyond its training data. In general, zero-shot prompting generates quick and efficient responses without training data, but compromises on the user’s control over the output. Meanwhile, few-shot prompting requires some handwritten data to be input, but the user would have vastly more control over its output. [4] In our case, for example, the group members initially hypothesised that few-shot prompting would be better than one-shot prompting to preserve uniformity across the classification of different reports.
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: `Here is a comprehensive list of hazard classifications, and their definitions:
Hazard_Code, Hazard_Name Hazard_Description,
${hazardDefinitionsConcatenated}
Identify potential hazard codes that are present in this report.
Example: "There were reports of lightning followed by thunderstorms in the southern region of Ecuador.
Response: "[MH0002, MH0003]"
Example: "Dengue fever outbreaks were recorded in southern Bangladesh."
Response: "[BI0059, BI0021]"`,
},
{
role: "user",
content: report,
},
],
Interestingly, in this project’s scenarios, zero-shot prompting elicited better responses than few-shot prompting. When prompted with even just one extra example, the LLM gave worse responses (i.e. matched less hazards than when no examples were given).
Upon further research, it was deduced that the LLM was possibly becoming “context stuffed” - that is, the context window was too full of unnecessary information such that the LLM could not extract the most relevant information. The surprise should not have been unexpected, considering that ChatGPT was prompted with the entire hazards taxonomy scheme database, whilst Llama2 already had its smaller context window preoccupied with the most crucial information. [5] However, this is just a hypothesis based on empirical evidence: more research would be needed to determine the actual cause of performance degradation.
In conclusion, within the boundaries of n-shot prompting, zero-shot prompting was determined to be the most promising.
1.1.3 Further refinements to prompt
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: `Here is a comprehensive list of hazard classifications, and their definitions:
Hazard_Code, Hazard_Name Hazard_Description,
${hazardDefinitionsConcatenated}
Identify potential hazard codes that are present in this report.`,
},
{
role: "user",
content: report,
},
],
Even though a generic zero-shot prompt was optimal for this project’s tool, it was still producing irrelevant answers and wildly inconsistent output. As thus, the group members decided that further refinements had to be made to the prompt. Further research elicited some syntactical techniques to acquire better responses:
- Clear syntax (structural hints) [7]
- Keeping simple [8]
- Identifying core requests
- Prioritising information
- Providing context
- Avoiding overly long prompts
- Using positive language
With this in mind, the project members once again restructured both the prompt for ChatGPT and Llama2.
model: "gpt-3.5-turbo",
messages: [
{
role: "system",
content: `Here is a comprehensive list of hazard classifications, and their definitions:
Hazard_Code, Hazard_Name Hazard_Description,
${hazardDefinitionsConcatenated}
You are HazardID, an AI assistant that helps people identify hazards in a given report.
It very important that you identify every hazard in the report.
You should attempt to infer other hazards that may be present,
even if not directly mentioned.
You MUST include all hazards that are directly mentioned in the report.`,
},
{
role: "user",
content: report,
},
],
In ChatGPT’s case, the prompt was refactored to first prioritise the definitions of hazards to make sure that it would minimise the likelihood of missing hazards present in the report. Then, it was explicitly given a core responsibility and context to what it was working on. The prompt was created as short as possible, with all following instructions briefly telling it to be very specific using positive language. Testing concluded that this was the optimal prompt for this project’s causes - it returned a coherent and comprehensive list of matched hazards.
prompt = f"""What is the likelihood that {hazard1} causes {hazard2}, bearing in mind:
{hazard1}: {def1}
{hazard2}: {def2}
"""
super_prompt = f"""
SYSTEM: We're evaluating the likelihood of various hazards causing specific outcomes.
Your responses should be one number between 0 and 5, following the below scale.
Include a short explanation for your score, as it helps understand the reasoning behind your assessment.
- 0: Almost never
- 1: Very Unlikely
- 2: Unlikely
- 3: Likely
- 4: Very likely
- 5: Almost always
Given the above, consider the following query:
USER: {prompt}
ASSISTANT:
"""
Similar to ChatGPT, the prompt given to Llama2 to generate the Association Matrix was refactored to first give further context as to what it was trying to achieve. In this case, however, this was perhaps more important than the hazard definitions, as the action of giving a score was top priority. A predefined scale was also included with the prompt to ensure that the LLM had no ambiguity over the scores, and also to make sure that the LLM provided uniform answers across the matrix.
1.1.4 Conclusion
In conclusion, the team dedicated the majority of their refinement phase to fine-tuning the prompt. This ensured that the tool fully leveraged the capabilities of the LLMs it employed, resulting in the generated answers being highly optimised.
1.2 Quantisation
It is well-known that LLMs are particularly resource intensive - Meta’s Llama-7b-chat with only 7 billion parameters, requires a minimum of 14GB modern VRAM to run without issues. In comparison, gpt-3.5-turbo, OpenAI’s cheapest commercially available LLM, is thought to contain about 20 billion parameters. [11] In short, running an LLM locally (possibly, to avoid paying the high costs associated with multiple invocations) requires hardware that may be hard to acquire for an individual.
This presented itself as a challenge mainly during the generation of the Association Matrix, where more than 90,000 LLM invocations had to be made to fill the matrix. Using an external API would be too expensive; so too would be hiring a large virtual machine. To bypass all of these concerns, the team looked into LLM quantisation - a process in which the size and memory usage of the LLM is reduced whilst the the quality is retained as much as possible. [12] The team had access to reasonably powerful commercially-available computing resources through SSH, which were still not powerful enough to run the full unquantised versions of Llama, but could certainly run some of the less resource-intensive quantised versions.
1.2.1 Available Hardware
The team had SSH access to UCL’s Computer Science Machines, which were equipped with the Intel Core i9-12900K (16-core) CPU, Nvidia RTX 3090Ti GPU (24GB VRAM), along with 128GB RAM. The goal was to utilise as much of these resources as possible to employ the quantised model with the least quality loss whilst still maintaining suitable invocation speeds. The time per invocation was especially important and uncompromisable, as there were 90,000 hazard pairs to run - even ten seconds per generation would yield 450,000 seconds, which would be over ten days!
1.2.2 Quantisation Methods and Effects
As mentioned previously, quantisation reduces the resource intensity of the LLM. This is done mainly through changing high-precision data representations to lower ones. For example, data held by 32-bit floating point numbers (FP32), are converted to a 4- or 8-bit integer (INT4, INT8). [13] It can be easily described using a compressed image as an analogy - more compressed images of lower quality can be stored in the same amount of space than their full-resolution counterparts.
Although reducing FP32 values to similarly represented FP16 values may be straightforward, it is more challenging to reduce FP32 values to e.g. a measly INT8 - INT8 can only represent 256 distinct values compared to the vast amount of value FP32 can represent. To achieve such downsizing, one must find the optimal method of projecting the FP32 weight value intervals ([min, max]) to the smaller range of the INT4 space. The affine quantisation scheme formula can be used to achieve this: [14]
where:
- represents the original FP32 value
- and represent quantisation parameters (scale and zero-point respectively)
- represents the quantised value corresponding to
N.B. Any values beyond the range of INT8 are clipped to the nearest representable value.
1.2.3 Picking Pre-Quantised Models for AssociationMatrix
Though there are significant benefits to using a custom-quantised model, it was decided that due to the short timescale, custom-quantisation was beyond the scope of the project. The team members thus began to experiment with differently pre-quantised versions of both Llama-2-7b-chat and Llama-2-13b-chat.
Although quantised versions of Llama-2-7b-chat were much faster in generation time than any quantised versions of Llama-2-13b-chat, Llama-7b-chat variants were eventually disregarded. This was in part due to its poor grasp of nuances - its ability to reason about intra-hazard associations was too rudimentary to progress with the matrix generation.
The team members briefly tested four different versions of Llama-2-13b-chat:
llama-2-13b-chat.Q3_K_M.ggufllama-2-13b-chat.Q4_K_M.ggufllama-2-13b-chat.Q5_K_M.ggufllama-2-13b-chat.Q8_0.gguf
These were variants of llama-2-13b-chat that were pre-quantised down to 3, 4, 5, and 8 bits respectively. Each variant was given a smaller set of associations to generate: instead of a 303x303 matrix, they were given a 5x5 matrix. All models were run using the same base code on the same CS machine. The average time taken to generate the 5x5 matrix was recorded. At the same time, a loss score was also recorded: this represented the total deviations from a similar matrix that was generated by GPT-4:
where A represents the loss score, and represent elements within the matrices produced by GPT-4 and Llama-models, respectively. This equation was chosen as a simplistic way of measuring how accurate the model responded in relation to GPT-4.
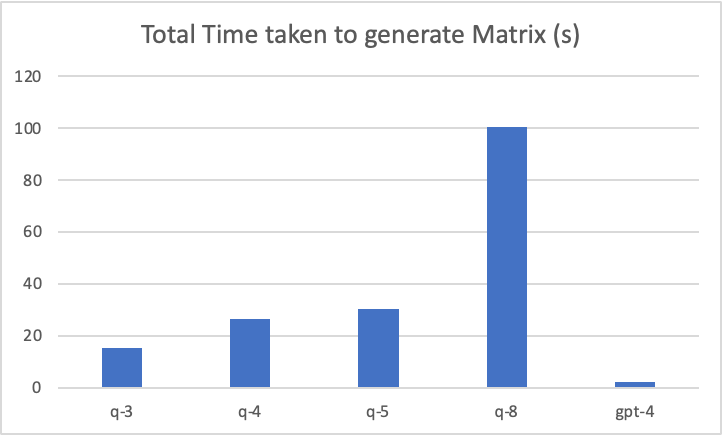
Figure 1.2.3a: Bar chart to compare the time to generate the matrix for different quantisation models. GPT-4 is included as reference.
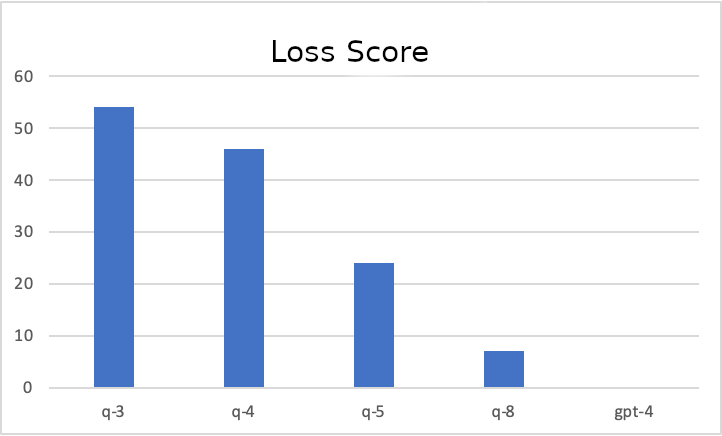
Figure 1.2.3b: Bar chart to measure the loss score for different quantisation models. GPT-4 is included as reference.
It was determined by the small experiment that the 5-bit quantised model was the best middle ground for the matrix generation - it was not too much slower than its further reduced counterparts, and provided for a reasonable accuracy score. As thus, the llama-2-13b-chat.Q5_K_M.gguf model was chosen to run the Association Matrix for more than 90,000 invocations on the CS machines.
Caveat: this experiment was not conducted with proper scientific protocols and methods in place. This experiment was designed solely to quickly and efficiently determine the best quantised model for this specific project. As thus, these results must not be taken as facts, and any genuine scientific references to this experiment must be fact-checked.
In this case, GPT-4’s generation was taken as factual evidence; however, this should not be done in real life. This experiment used GPT-4 as facts to illustrate the relative performance of objectively inferior LLMs.
2. Technology Review
2.1 BERT Multi-label Classification Approach
As the problem is essentially a form of text classification, the first long term solution ideated was to train a multi-label classification model. This approach involves collecting a large number of reports tagged under the UNDRR-ISC guidelines and using them to train the model. We intended to use BERT, as it is open source, highly performant, and there is a wealth of information on how best to use it. The large number of labels (303) makes training a single model extremely difficult, as the model outputs are “diluted” by the number of unused labels. We found that after training the model would often return a matrix of zeros, as this would guarantee 80% of the outputs were correct. Furthermore, the complete lack of any pre-existing labeled data to train the model meant that we would have to create the training dataset ourselves
To combat this, an architecture was produced that breaks the model into several sub models, each trained to identify a specific category of hazards. Doing this allowed for more effective fine tuning, and reduced the size of the required training dataset. After performing a trial test by creating a dataset of 200 labeled reports and attempting to train one of the sub models, BERT only had an accuracy of 67.2%. The team realised that producing the required amount of training data was outside of the scope of this project, and so, after a discussion with the client, decided to abandon a BERT based approach.
2.2 Rules-Based Approach
The keywords-matching rules-based approach was developed in tandem to the decision trees approach as a viable alternative. This approach uses a keywords matching system - using a natural language framework, the submitted report is scanned for certain keywords that correlate to certain hazards. Once a hazard is matched, the clarification question is surfaced to the user for confirmation.
The keywords list for each hazard was generated using the GPT-4 LLM. This was to ensure as much coverage as possible.
2.3 ChatGPT-3.5 Approach
After the decision trees approach was abandoned due to the lack of training data for BERT, the group switched to employing the use of an LLM to scan the report for matching hazards. The ChatGPT API is given the full report, as well as a database containing information on the hazards (such as the hazard codes, descriptions, etc). The GPT API would return a list of potential hazards, and once again the clarification questions are surfaced to the user for confirmation.
2.4 Rules-Based vs. ChatGPT-3.5
It was decided that both the Rules-Based version and the ChatGPT-3.5 based version would be kept in the final product. This is due to the fact that the group members rated them equally - both had advantages and disadvantages over one another.
| Model | Processing Speed | Number of questions generated | Accuracy of questions | Percentage of hazards in report identified | Price |
|---|---|---|---|---|---|
| Rules-Based | Almost instant | Many | Lower | less than 90% | None |
| LLM-guided | less than 10 seconds | Less | Higher | less than 70% | $0.02 per invocation |
In general, the rules-based model had a more comprehensive set of clarification questions, some of which were simply incorrect and irrelevant to the report. This was possibly due to the keywords matching aspect - this model could not differentiate between (civil) unrest and (civil) infrastructure damage, for example. Despite the model’s overzealous nature, it was still missing some implied hazards. For example, if El Nino was mentioned, the rules-based version would fail to pick up on potential extreme weather consequences, such as wildfires.
On the other hand, the GPT-based model had far fewer clarification questions, and the matched hazards were generally relevant and correct. The large language model was indeed more accurate, but its quality-over-quantity strategy was a double-edged sword - it matched less hazards in the report than the rules-based version.
Both models were intensively evaluated and tested, the results of which are in the Evaluation section.
2.5 Different Open-Source LLMs
As mentioned prior, the Association Matrix was generated using the Llama2 LLM. The group members chose this model over others, as it balanced out performance, accuracy, and ethical moderation. However, during the planning phase, several other open-source LLM’s were considered.
2.5.1 Mistral-7b
Mistral-7b was a very competitive model that the group was considering. Despite having almost half the parameters that Llama2-13b-chat had, it outperformed Llama2 on most metrics. The big caveat with this model was the fact that it was uncensored - there was little to no moderation on its responses. [15] Since the Association Matrix generator also recorded justifications, it was too much of a risk to allow an unmoderated LLM to generate documents that would potentially be read by people around the world. As thus, Llama2 was selected instead - for the purposes of this project, the performance and accuracy gain from using Mistral-7b was rather marginal.
2.5.2 BLOOM
BLOOM was another open-source LLM that initially seemed promising due to its ability to support several different languages out of the box. The group members initially liked the idea as they considered the international nature of the IFRC organisation. However, resources to run a 176B parameter LLM were hard to come by - the group members eventually scrapped this model due to logistical problems.
2.5.3 GPT-2
GPT-2, the precursor to the famous GPT-3.5 and GPT-4 LLMs, was also briefly considered, since it was closest in nature to those accredited LLMs. However, this was scrapped due to GPT-2’s heavy biases and outdated training data.
2.6 Identifying Similar Hazards
To identify which hazards are likely to be confused with one another, we needed to define some sort of objective metric for how similar any two hazards are. This is a complex challenge, as the complexities of natural language make objective metrics incredibly difficult to extract.
2.6.1 Embeddings
Our approach to solving this problem makes use of embeddings, which are a method of encoding semantic meaning as a higher dimensional vector. This vector encapsulates the “meaning” of a piece of text, and, being a mathematical construct, allows you to perform calculations and comparisons between different vectors.
2.6.2 Cosine Similarity
Cosine similarity can be used to assess the degree of similarity between these items based on the context in which they appear.
The cosine similarity between two vectors (A and B) is calculated by taking the dot product of the vectors and then dividing that product by the product of the vectors' magnitudes. The formula for cosine similarity is:
where:
- A · B is the dot product of the vectors A and B,
- and are the magnitudes (or Euclidean norms) of the vectors A and B, respectively.
The result of the cosine similarity metric is a value between -1 and 1:
- A cosine similarity of 1 means the vectors are identical.
- A cosine similarity of 0 means the vectors are orthogonal (independent) to each other.
- A cosine similarity of -1 means the vectors are diametrically opposite.
2.7 Existing LLM APIs
As previously mentioned, the decision was made to use the OpenAI GPT API to perform the LLM procession operations for our core API. We had two options to choose between, GPT-3.5-Turbo and GPT-4.
2.7.1 GPT-3.5-Turbo
GPT-3.5 is an iteration of the Generative Pre-trained Transformer models developed by OpenAI, positioned between GPT-3 and GPT-4 in terms of its capabilities and advancements. In our testing, we found that it could be prone to hallucinating hazard identifications, even occasionally making up new hazards. This was largely resolved by placing the API in JSON output mode, and providing the AI with a schema in the prompt. This rigidity caused the AI to operate within the bounds of our application, improving performance. GPT3.5 Turbo is also, as the name implies, incredibly fast to respond. This speed allowed us to perform our analysis in real time, without needing the user to wait upwards of 30 seconds for the first round of their classification.
2.7.2 GPT-4
GPT-4 is the latest model produced by OpenAI, and is leaps and bounds more intelligent than GPT-3.5-turbo. While this is impressive, we only need the model to be able to perform 1-shot text classification, and as such this extra power would be wasted. One cost of this increased model power is that each call to GPT-4 is an order of magnitude more expensive than one to GPT-3.5. A second downside is the time it takes to respond. Our testing showed that while GPT-3.5-turbo averaged a mere 6 seconds per classification, GPT-4 could take upwards of 30. When this was brought to the client’s attention, we were instructed to use GPT-3.5-turbo instead.
3. Summary of Technical Decisions
The culmination of extensive research efforts resulted in the refinement and integration of optimal technical aspects into the tool's implementation.
3.1 Main Tool
The main tool was split into two different models: the Rules-Based (Keywords-Matching) and the Machine Learning (ChatGPT-3.5 API) classification models.
Both models were left in the final deliverable to give users a choice. One could choose to have a smaller and more accurate pool of clarification questions for a faster and more nuanced tagging process, or one could opt for a larger pool of clarification questions to be able to match as many hazards as possible.
3.2 Association Matrix
The Association Matrix used the 5-bit quantised model of the Llama-2-13b-chat model for a balanced mix between speed and accuracy.
3.3 Confusion Matrix
The Confusion Matrix used an embeddings model provided by the sentence_transformers library, as well as the cosine similarity measure to generate the likelihood of two hazards being confused.
4. References
[1] LLM prompting guide. (n.d.). https://huggingface.co/docs/transformers/main/en/tasks/prompting
[2] Musgrave, K. (2023, October 30). LLM prompting: The basic techniques. Determined AI. https://www.determined.ai/blog/llm-prompting
[3] Tam, A. (2023, July 20). What are zero-shot prompting and few-shot prompting. MachineLearningMastery.com. https://machinelearningmastery.com/what-are-zero-shot-prompting-and-few-shot-prompting/
[4] Sharma, V. (2023, July 25). A comparative analysis of zero shot vs few shot prompting. Enterprise Search and Analytics. https://www.searchunify.com/infographic/a-comparative-analysis-of-zero-shot-vs-few-shot-prompting/#:~:text=While%20zero-shot%20prompting%20enables,minimal%20examples%20for%20enhanced%20accuracy.
[5] Catav, A. (n.d.). Less is more: Why use retrieval instead of larger context windows. Pinecone. https://www.pinecone.io/blog/why-use-retrieval-instead-of-larger-context/
[6] Understanding latency in LLM: The impact of Token Generation on response time. Proxet. (n.d.). https://www.proxet.com/blog/llm-has-a-performance-problem-inherent-to-its-architecture-latency
[7] Lundberg, S. (2023, December 14). The art of prompt design: Use clear syntax. Medium. https://towardsdatascience.com/the-art-of-prompt-design-use-clear-syntax-4fc846c1ebd5
[8] Shah, S. (2023, October 18). Prompt tuning: A powerful technique for adapting LLMS to new tasks. Medium. https://medium.com/@shahshreyansh20/prompt-tuning-a-powerful-technique-for-adapting-llms-to-new-tasks-6d6fd9b83557
[9] Taivo Pungas. (2024, January 23). GPT-3.5 and GPT-4 response times. https://www.taivo.ai/__gpt-3-5-and-gpt-4-response-times/
[10] conda78o. (2022, April 24). Does openai charge for both prompt and completion?. OpenAI Developer Forum. https://community.openai.com/t/does-openai-charge-for-both-prompt-and-completion/17276/2
[11] Wodecki, B. (2023, November 7). Ai News Roundup: Microsoft may have leaked CHATGPT parameters. AI Business Informs, educates and connects the global AI community. https://aibusiness.com/verticals/-ai-news-roundup-microsoft-may-have-leaked-chatgpt-parameters#close-modal
[12] Deci, & Deci. (2024, March 8). How LLM quantization impacts model quality. Deci. https://deci.ai/blog/how-llm-quantization-impacts-model-quality/#:~:text=Quantization of large language models,devices with limited computational capabilities.
[13] Talamadupula, K. (2024, February 21). A guide to quantization in LLMS. Symbl.ai. https://symbl.ai/developers/blog/a-guide-to-quantization-in-llms/#:~:text=Quantization is a model compression,to one that holds less.
[14] Rajpurohit, R. (2023, August 20). Understanding quantization: Optimizing AI models for efficiency. Medium. https://medium.com/@rakeshrajpurohit/understanding-quantization-optimizing-ai-models-for-efficiency-bf7be95efae3
[15] Mistral 7B vs LLAMA2: Which performs better. Mistral 7B vs Llama2: Which Performs Better. (n.d.). https://www.e2enetworks.com/blog/mistral-7b-vs-llama2-which-performs-better-and-why#:~:text=Mistral 7B significantly outperforms Llama2,win that showcases its capabilities.